Performance Overview
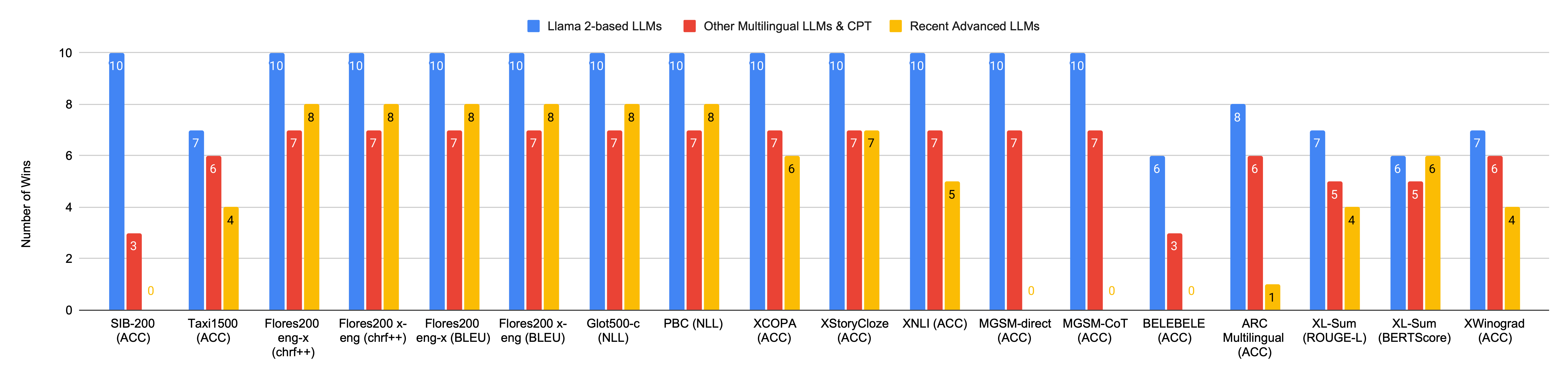
The number of wins, i.e., the number of times EMMA-500 achieves the best or superior performance compared to other models in the same category across various evaluation tasks and benchmarks. We compare our EMMA-500 Llama 2 7B model to decoder-only LLMs of similar parameter size, including (i) 10 Llama 2-based LLMs, (ii) 7 multilingual LLMs and CPT models, and (iii) 8 recent advanced LLMs. If EMMA-500 scores higher than all compared models on a specific benchmark, it is considered a winning case for that particular evaluation. Our EMMA-500 Llama 2 model outperforms most Llama 2-based, multilingual LLMs and CPT models. Remarkably, our model achieves the best performance on Flores200, Glot500-c, and PBC among all the compared baselines. Check out our paper for details!