Data Mix Composition
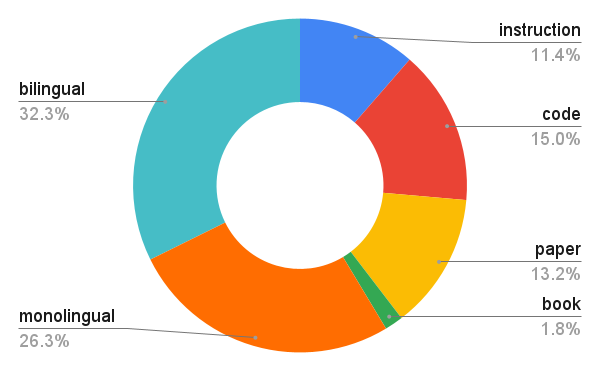
Data mix 1: bilingual
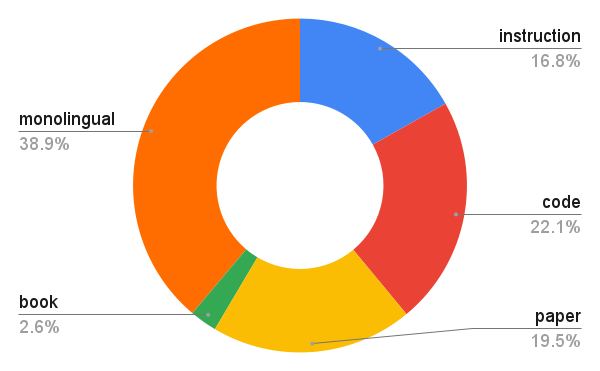
Data mix 2: monolingual
This paper investigates a critical design decision in the practice of massively multilingual continual pre-training --- the inclusion of parallel data. Specifically, we study the impact of bilingual translation data for massively multilingual language adaptation of the Llama3 family of models to 500 languages. To this end, we construct a bilingual translation corpus named MaLA, containing data from more than 2,500 language pairs. Subsequently, we develop the EMMA-500 Llama 3 suite of four massively multilingual models --- continually pre-trained from the Llama 3 family of base models extensively on diverse data mixes up to 671B tokens --- and explore the effect of continual pre-training with or without bilingual translation data. Comprehensive evaluation across 7 tasks and 12 benchmarks demonstrates that bilingual data tends to enhance language transfer and performance, particularly for low-resource languages. We open-source the MaLA corpus, EMMA-500 Llama 3 suite artefacts, code, and model generations.
1 We use MaLA and EMMA to name the corpus and models, following the naming convention of EMMA-500 Llama 2 (Ji et al., 2024), which is not an artifact of this paper. MaLA and EMMA are a collection of corpora and models. In this paper, ``Mono'' and ``Bi'' indicate CPT on monolingual (Mix 2) and bilingual (Mix 1) mixes, respectively.
While multilingual models can achieve broad coverage, perfect uniformity across all tasks and languages remains an unattainable goal. However, we show that multilingual performance and language equality can be pushed forward with parallel training data.
2 A monolingual mix (Mix 2) contains monolingual data in different languages but not in the aligned format as parallel data.
| Categories | Language Pairs | Tokens |
|---|---|---|
| very high | 4 | 8.5E+10 |
| high | 83 | 2.1E+11 |
| medium-high | 67 | 4.7E+10 |
| medium | 281 | 6.4E+10 |
| medium-low | 508 | 2.0E+10 |
| low | 655 | 2.5E+09 |
| very low | 909 | 1.8E+08 |
| sum | 2507 | 4.3E+11 |
Data mix 1: bilingual
Data mix 2: monolingual
| Base Model | Data Mix | Our Models | Tokens |
|---|---|---|---|
| Llama 3 | Monolingual (Mix 2) | 🤗 EMMA Llama 3 8B Mono | 419B |
| Bilingual (Mix 1) | 🤗 EMMA Llama 3 8B Bi | 671B | |
| Llama 3.1 | Monolingual (Mix 2) | 🤗 EMMA Llama 3.1 8B Mono | 419B |
| Bilingual (Mix 1) | 🤗 EMMA Llama 3.1 8B Bi | 671B |
| Tasks | Dataset | Metric | Samples/Lang | N Lang | Domain | Results |
|---|---|---|---|---|---|---|
| Text Classification | 🤗 SIB200 | Accuracy | 204 | 205 | Misc | [Results] |
| Taxi1500 | Accuracy | 111 | 1507 | Bible | [Results] | |
| Commonsense Reasoning | 🤗 XCOPA | Accuracy | 600 | 11 | Misc | [Results] |
| 🤗 XStoryCloze | Accuracy | 1870 | 11 | Misc | [Results] | |
| Natural Language Inference | 🤗 XNLI | Accuracy | 2490 | 15 | Misc | [Results] |
| Machine Translation | 🤗 FLORES-200 | BLEU, chrF++ | 1012 | 204 | Misc | [Results] |
| Summarization | 🤗 XL-Sum | ROUGE-L, BERTScore | 2537 | 44 | News | [Results] |
| 🤗 MassiveSumm Long | ROUGE-L, BERTScore | 3908 | 55 | News | [Results] | |
| 🤗 MassiveSumm Short | ROUGE-L, BERTScore | 5538 | 88 | News | [Results] | |
| Machine Comprehension | 🤗 BELEBELE | Accuracy | 900 | 122 | Misc | [Results] |
| ARC multilingual | Accuracy | 1170 | 31 | Misc | [Results] | |
| Math | 🤗 MGSM direct | Accuracy | 250 | 10 | Misc | [Results] |
| 🤗 MGSM CoT | Accuracy | 250 | 10 | Misc | [Results] |
@article{ji2025emma2,
title={Massively Multilingual Adaptation of Large Language Models Using Bilingual Translation Data},
author={Shaoxiong Ji and Zihao Li and Jaakko Paavola and Hengyu Luo and Jörg Tiedemann},
year={2025},
journal={arXiv preprint 2506.00469},
url={https://arxiv.org/abs/2506.00469},
}